DeepSeek V3: Redefining AI Capabilities for the Next Generation
advertisement
In the fast-paced realm of artificial intelligence, DeepSeek has once again made waves with the update of its AI model to V3. This upgrade has sent ripples through the global tech community, especially among the 20-40-year-old demographic in Western countries, who are at the forefront of embracing and leveraging cutting-edge technologies.

The journey of DeepSeek's model evolution has been nothing short of remarkable. DeepSeek-V3, with its staggering 671 billion parameters, represents a quantum leap in the field of large-language models (LLMs). What sets it apart is not just its size but the innovative architecture it employs. It utilizes a mixture-of-experts (MoE) transformer design. In the specified configuration, merely 37 billion out of the total 671 billion parameters remain operational at any given point in time. This is similar to having a team of specialists, where different subsets of parameters, or "experts," are called upon to handle different types of inputs. The MoE architecture is preceded by a gating module that intelligently selects the most suitable expert(s) based on the input, much like a conductor choosing the right musicians for a particular musical passage. This approach leads to more efficient processing, as not all parameters are used for every output, resulting in reduced energy consumption and faster runtimes compared to models that use all parameters uniformly.
The training procedure of DeepSeek-V3 stands as a compelling testament to the company’s exceptional engineering prowess.Trained on approximately 15 trillion tokens, the model has ingested a vast amount of diverse data. Notably, there is a higher proportion of coding and math data compared to its predecessor, DeepSeek-V2. This focus on specific data domains has sharpened DeepSeek-V3's performance in coding and math tasks. In coding benchmarks, it has dominated in five out of seven tests, showcasing its ability to generate high-quality code. For example, in front-end development tasks, it can generate complex HTML, CSS, and JavaScript code for an interactive web page with smooth animations and responsive layouts in a matter of minutes. In the realm of math, it has achieved exceptional scores, outperforming many of its counterparts in solving complex equations and logical problems.
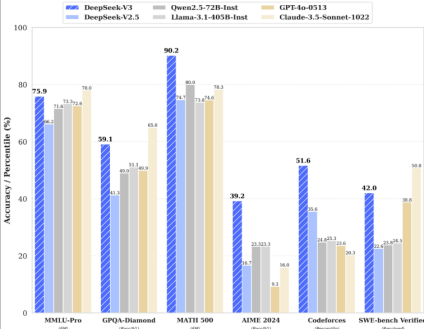
The training was further enhanced by fine-tuning on a wide array of tasks using the output generated by DeepSeek-R1 and DeepSeek-V2.5. Additionally, the reinforcement learning algorithm, group relative policy optimization, was employed to further optimize its performance across different domains. This iterative training process has enabled DeepSeek-V3 to adapt and excel in various real-world scenarios.
Another interesting aspect of DeepSeek-V3 is its use of multi-head latent attention. This technique is crucial as it saves memory during execution relative to other attention mechanisms. It also combines dedicated (routed) and shared experts, similar to DeepSeek-V2. For a specific input, the model selects eight experts from a total of 256, alongside which it also leverages a shared expert responsible for processing all incoming inputs.This integration of routed and shared experts strikes an optimal balance between specialization and generalization.
The release of DeepSeek-V3 has significant implications for the 20-40-year-old users in Western countries. For developers in this age group, the model's enhanced coding capabilities mean faster development times and more reliable code generation. It can serve as a powerful coding assistant, helping to write code in multiple programming languages, detect and fix errors, and even optimize code for better performance. In the academic and research community, the improved math and reasoning abilities of DeepSeek-V3 can aid in solving complex problems in fields such as physics, engineering, and data science.

In conclusion, DeepSeek's update to V3 is not just an incremental improvement but a revolutionary step in the development of AI models. With its advanced architecture, extensive training, and remarkable performance in key areas, it is well-positioned to shape the future of AI-driven applications and services, catering particularly well to the needs and interests of the young and tech-savvy audience in Western countries.
(Writer:Dick)
Related Articles




